파드와 컨테이너
September 2024 (2553 Words, 15 Minutes)
파드와 컨테이너
Pod & Pause Container
Pod는 1개 이상의 컨테이너로 구성된 컨테이너 묶음입니다. 이때 Pause Container가 Network, IPC, UTS Namespace를 생성하여 공유, 유지를 합니다.
CRI
쿠버네티스는 3가지의 표준 인터페이스를 제정해서 모듈 형태로 갈아끼울수있게 만들었습니다.

그중 CRI의 이야기입니다.

- Container Runtime : kubelet → CRI → High Level Runtime (containerd) ← OCI → Low Level Runtime (Runc)
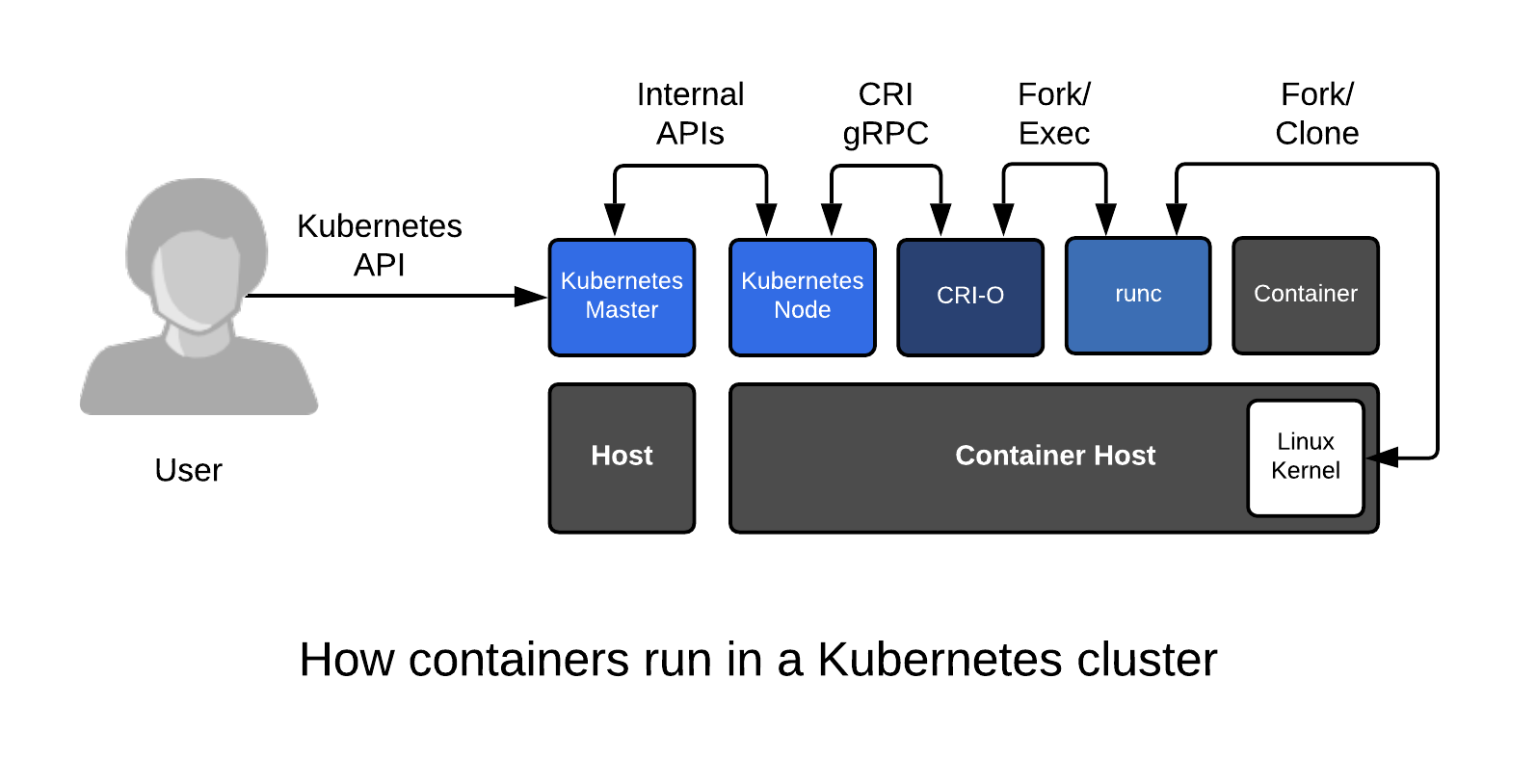
https://insujang.github.io/2019-10-31/container-runtime/
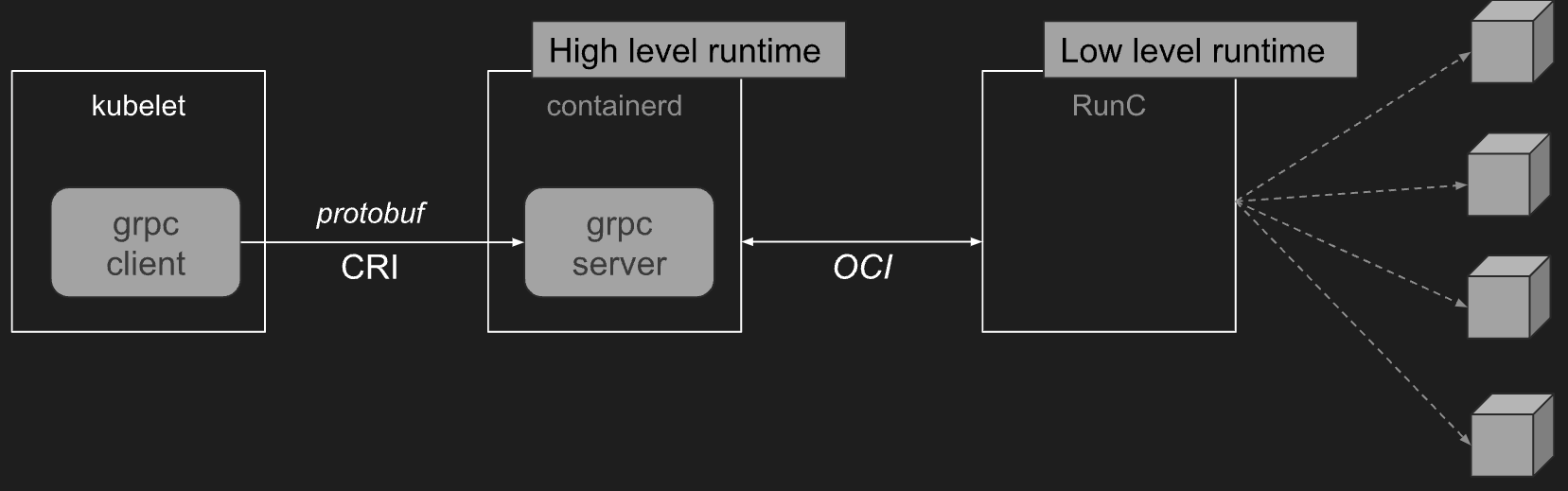
https://kubernetes.io/blog/2016/12/container-runtime-interface-cri-in-kubernetes/
- 쿠버네티스 노드의 가장 낮은 계층(Low Level)에는 컨테이너를 시작하고 중지하는 것 외에도 소프트웨어가 있습니다. 이를 “컨테이너 런타임(Runc 등)“이라고 합니다. 가장 널리 알려진 컨테이너 런타임은 Docker이지만 이 분야에서 유일한 것은 아닙니다. 사실, 컨테이너 런타임 공간은 빠르게 진화해 왔습니다. 쿠버네티스를 더 확장 가능하게 만들기 위한 노력의 일환으로, “CRI“라고 하는 쿠버네티스의 컨테이너 런타임을 위한 새로운 플러그인 API를 개발해 왔습니다.
- CRI는 kubelet이 재컴파일할 필요 없이 다양한 컨테이너 런타임을 사용할 수 있도록 해줍니다. 프로토콜 버퍼 와 gRPC API , 라이브러리 로 구성되어 있으며, 추가 사양과 도구가 활발하게 개발 중입니다.
-
명확하게 정의된 추상화 계층을 제공함으로써 장벽을 제거하고 개발자가 컨테이너 런타임을 빌드하는 데 집중할 수 있도록 합니다. 이는 플러그형 컨테이너 런타임을 진정으로 활성화하고 보다 건강한 생태계를 구축하기 위한 작지만 중요한 단계입니다.
-
CRI
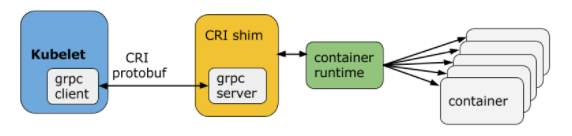
- Kubelet은 gRPC 프레임워크를 사용하여 Unix 소켓을 통해 컨테이너 런타임(또는 런타임용 CRI shim)과 통신합니다.
- Pod는 리소스 제약이 있는 격리된 환경의 애플리케이션 컨테이너 그룹으로 구성됩니다. CRI에서 이 환경을 PodSandbox라고 합니다.
- 우리는 의도적으로 컨테이너 런타임이 내부적으로 작동하는 방식에 따라 PodSandbox를 다르게 해석할 수 있는 여지를 남겨둡니다. 하이퍼바이저 기반 런타임의 경우 PodSandbox는 가상 머신을 나타낼 수 있습니다. Docker와 같은 다른 경우 Linux 네임스페이스일 수 있습니다. PodSandbox는 Pod 리소스 사양을 준수해야 합니다. v1alpha1 API에서 이는 kubelet이 생성하여 런타임에 전달하는 Pod 수준 cgroup 내의 모든 프로세스를 시작하여 달성됩니다.
- 포드를 시작하기 전에 kubelet은 RuntimeService.RunPodSandbox를 호출하여 환경을 만듭니다. 여기에는 포드에 대한 네트워킹 설정(예: IP 할당)이 포함됩니다. PodSandbox가 활성화되면 개별 컨테이너를 독립적으로 생성/시작/중지/제거할 수 있습니다. 포드를 삭제하기 위해 kubelet은 PodSandbox를 중지하고 제거하기 전에 컨테이너를 중지하고 제거합니다.
- Kubelet은 RPC를 통해 컨테이너의 수명 주기를 관리하고, 컨테이너 수명 주기 후크와 활성/준비 확인을 실행하며, Pod의 재시작 정책을 준수합니다.
Pod
컨테이너 애플리케이션의 기본 단위를 파드(Pod)라고 부르며,
파드는 1개 이상의 컨테이너로 구성된 컨테이너의 집합 - 링크 , code
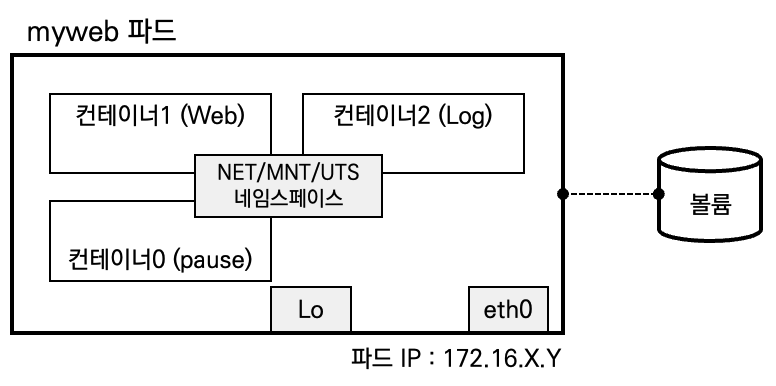
- Pod 는 1개 이상의 컨테이너를 가질 수 있습니다
- sidecar 패턴으로 구현되기도하며, init 컨테이너를 sidecar처럼 구현하는 방법도 가능합니다.
- Pod 내에 실행되는 컨테이너들은 반드시 동일한 노드에 할당되며 동일한 생명 주기를 갖습니다 → Pod 삭제 시, Pod 내 모든 컨테이너가 삭제됩니다. → 하지만 컨테이너들의 종료를 Triggering 하는것은 별개입니다. pod의 lifecycle과 container의 lifecycle 은 별개입니다. https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/ https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/
- Pod IP - Pod 는 노드 IP 와 별개로 클러스터 내에서 접근 가능한 IP를 할당 받으며, 다른 노드에 위치한 Pod 도 NAT 없이 Pod IP로 접근 가능 ⇒ 요걸 CNI 해줌!
- IP 공유 - Pod 내에 있는 컨테이너들은 서로 IP를 공유, 컨테이너끼리는 localhost 통해 서로 접근하며 포트를 이용해 구분
- pause 컨테이너가 ‘parent’ 처럼 network ns 를 만들어 주고, 내부의 컨테이너들은 해당 net ns 를 공유 ← 세상에서 제일 많이 사용되는 컨테이너!
- 쿠버네티스에서 pause 컨테이너는 포드의 모든 컨테이너에 대한 “부모 컨테이너” 역할을 합니다 - Link
- Pause 컨테이너에는 두 가지 핵심 책임이 있습니다.
- 첫째, 포드에서 Linux 네임스페이스 공유의 기반 역할을 합니다.
- 둘째, PID(프로세스 ID) 네임스페이스 공유가 활성화되면 각 포드에 대한 PID 1 역할을 하며 좀비 프로세스를 거둡니다.
- volume 공유 - Pod 안의 컨테이너들은 동일한 볼륨과 연결이 가능하여 파일 시스템을 기반으로 서로 파일을 주고받을 수 있음
- Pod는 리소스 제약이 있는 격리된 환경의 애플리케이션 컨테이너 그룹으로 구성됩니다. CRI에서 이 환경을 PodSandbox라고 합니다.
- 포드를 시작하기 전에 kubelet은 RuntimeService.RunPodSandbox를 호출하여 환경을 만듭니다. (파드 네트워킹 설정 ’IP 할당’ 포함)
- Kubelet은 RPC를 통해 컨테이너의 수명 주기를 관리하고, 컨테이너 수명 주기 후크와 활성/준비 확인을 실행하며, Pod의 재시작 정책을 준수합니다
https://github.com/kubernetes/kubernetes/blob/master/build/pause/linux/pause.c
int main(int argc, char **argv) {
int i;
for (i = 1; i < argc; ++i) {
if (!strcasecmp(argv[i], "-v")) {
printf("pause.c %s\n", VERSION_STRING(VERSION));
return 0;
}
}
if (getpid() != 1)
/* Not an error because pause sees use outside of infra containers. */
fprintf(stderr, "Warning: pause should be the first process\n");
if (sigaction(SIGINT, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)
return 1;
if (sigaction(SIGTERM, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)
return 2;
if (sigaction(SIGCHLD, &(struct sigaction){.sa_handler = sigreap,
.sa_flags = SA_NOCLDSTOP},
NULL) < 0)
return 3;
for (;;)
pause();
fprintf(stderr, "Error: infinite loop terminated\n");
return 42;
}
pause 컨테이너의 구현부는 굉장히 간단합니다.
대충… SIGINT, TERM, CHLD 에 대한 처리를 한다는건데,
pause() 함수를 사용하여 종료신호까지 무한대기하는 간단한 함수입니다.
실습해보기
POD 배포 및 격리 확인
# [터미널1] myk8s-worker bash 진입 후 실행 및 확인
docker exec -it myk8s-worker bash
# 확인 : 파드내에 pause 컨테이너와 metrics-server 컨테이너, 네임스페이스 정보
pstree -aclnpsS
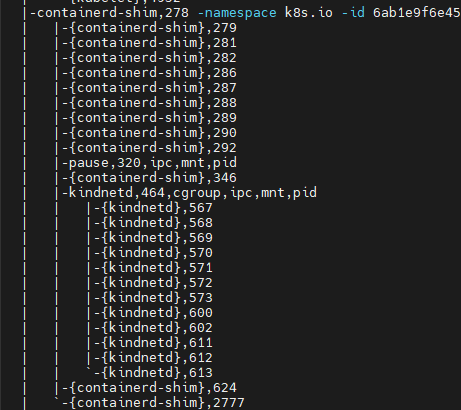
한개 컨테이너에 대한 격리정보입니다.
CGROUP, IPC, MNT, PID 등의 정보가 공통적으로 적용된걸 확인 할 수 있습니다.
# 네임스페이스 확인 : lsns - List system namespaces
# 해당 파드에 pause 컨테이너는 호스트NS와 다른 5개의 NS를 가짐 : mnt/pid 는 pasue 자신만 사용, net/uts/ipc는 app 컨테이너를 위해서 먼저 생성해둠
lsns -p 320
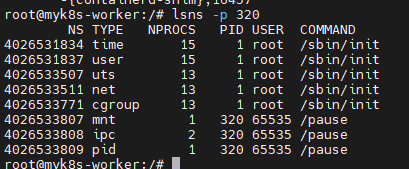
# app 컨테이너는 호스트NS와 다른 6개의 NS를 가짐 :
# mnt/pid/cgroup 는 자신만 사용, net/uts/ipc는 pause 컨테이너가 생성한 것을 공유 사용함
lsns -p $(pgrep python3)

# 특정 소켓 파일을 사용하는 프로세스 확인
lsof /run/containerd/containerd.sock

ss -xl | egrep 'Netid|containerd'

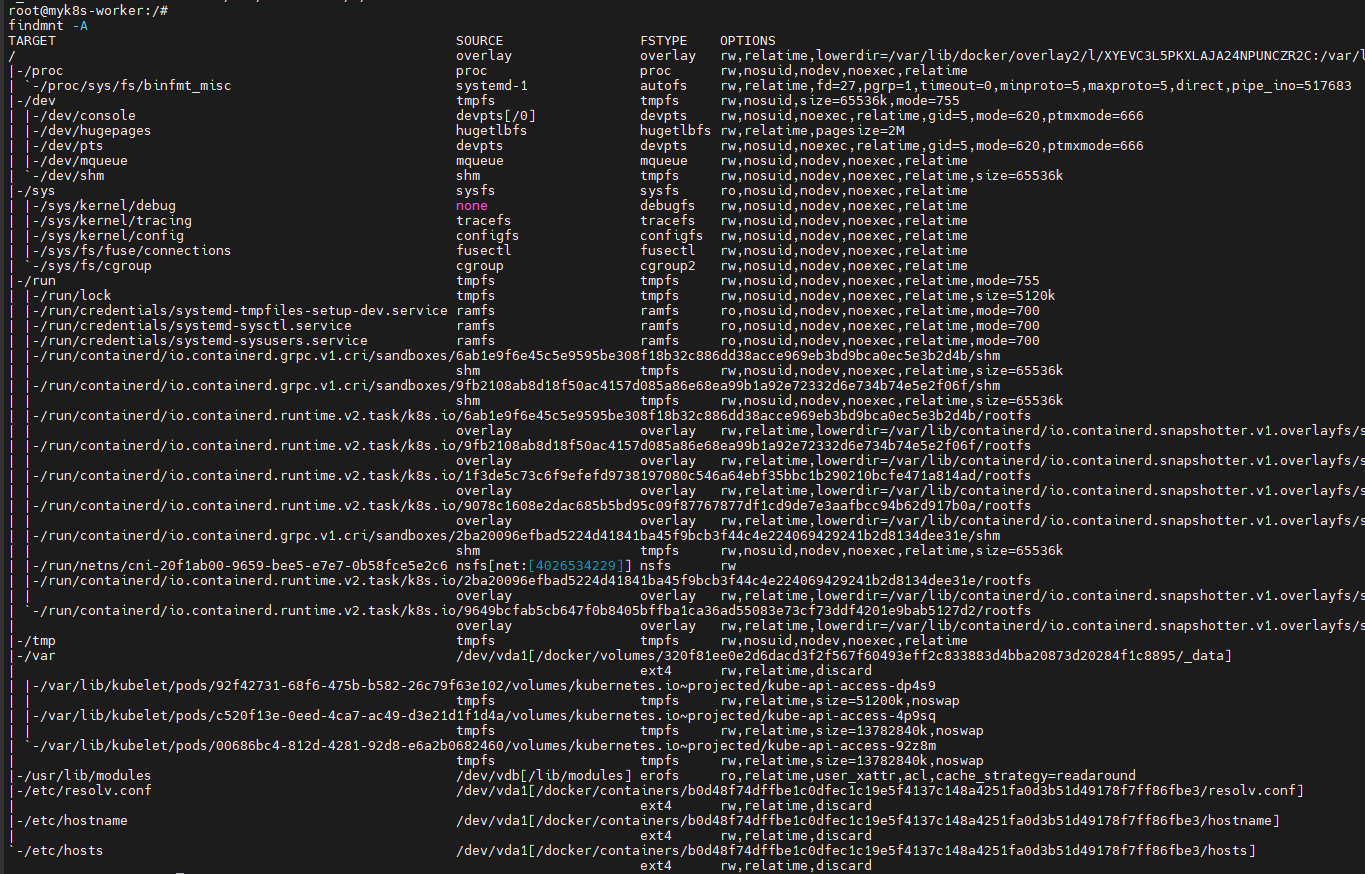
findmnt -A
myweb2 파드
myweb2 파드에 2개의 컨테이너를 띄워봅니다.

그림 가운데 uts ns 추가 필요
- myweb2.yaml : containers 가 복수형을 주목!
apiVersion: v1
kind: Pod
metadata:
name: myweb2
spec:
containers:
- name: myweb2-nginx
image: nginx
ports:
- containerPort: 80
protocol: TCP
- name: myweb2-netshoot
image: nicolaka/netshoot
command: ["/bin/bash"]
args: ["-c", "while true; do sleep 5; curl localhost; done"] # 포드가 종료되지 않도록 유지합니다
terminationGracePeriodSeconds: 0
배포!
kubectl apply -f https://raw.githubusercontent.com/gasida/NDKS/main/3/myweb2.yaml
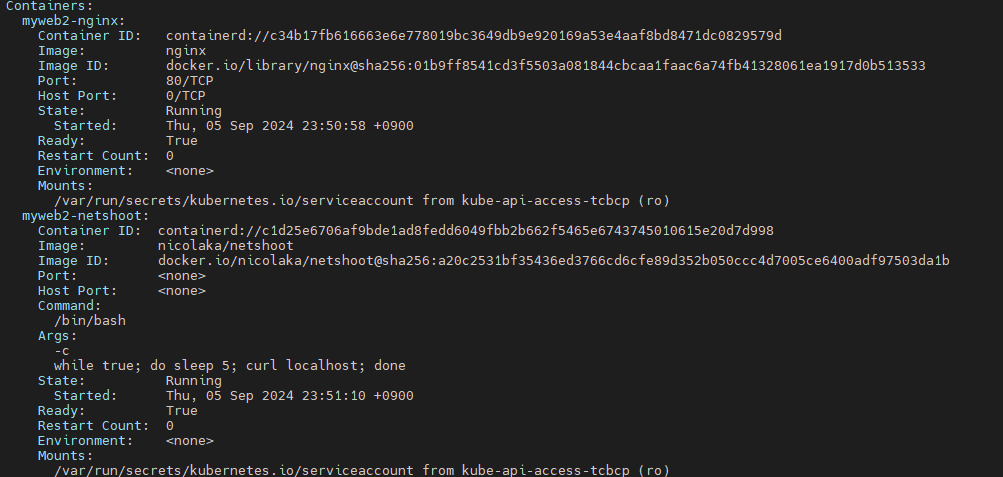
생성된 컨테이너는 두개가있지만 두 컨테이너간의 동작방식이 조금 다릅니다.
ifconfig
ss -tnlp
curl localhost # nginx 컨테이너가 아닌데, 로컬 접속 되고 tcp 80 listen 이다. 왜그럴까?
ps -ef # nginx 프로세스 정보가 안보이는데...
이런 정보들을 조회해보면 프로세스는 서로 조회가 안되거든요
노드에서 직접 확인해봅시당
crictl ps | grep myweb2
NGINXPID=$(ps -ef | grep 'nginx -g' | grep -v grep | awk '{print $2}')
echo $NGINXPID
lsns -p $NGINXPID
NETSHPID=$(ps -ef | grep 'curl' | grep -v grep | awk '{print $2}')
echo $NETSHPID
lsns -p $NETSHPID
PAUSEPID=$(lsns -p $NETSHPID | grep pause | awk '{print $4}' | sort -u | head -1)**
echo $PAUSEPID
lsns -p $PAUSEPID
밑에서 단일 컨테이너와 동일하게 확인합니다.
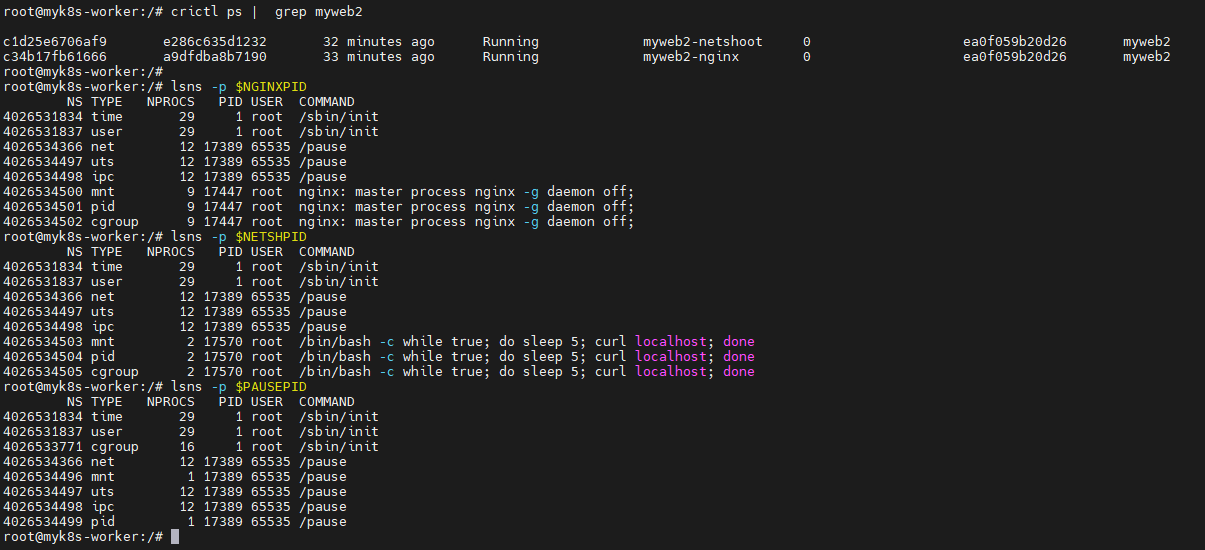
한 파드 내의 각 컨테이너의 네임스페이스 정보 확인
- time, user 네임스페이스는 호스트와 같음, 격리하지 않음
- mnt, uts, pid 네임스페이스는 컨테이너별로 격리
- ipc, uts, net 네임스페이스는 파드 내의 컨테이너 간 공유 (IPC : 컨테이너 프로세스간 공유 - signal, socket, pipe 등)
- Pause 컨테이너는 IPC, Network, UTS 네임스페이스를 생성하고 유지 -> 나머지 컨테이너들은 해당 네임스페이스를 공유하여 사용
- 유저가 실행한 특정 컨테이너가 비정상 종료되어 컨터이너 전체에서 공유되는 네임스페이스에 문제가 발생하는 것을 방지
Flannel CNI
쿠버네티스의 3가지의 표준 인터페이스 중 네트워크 인터페이스에 대한 설명입니다.

Flannel
- Flannel runs a small, single binary agent called
flanneldon each host, and is responsible for allocating a subnet lease to each host out of a larger, preconfigured address space. → 모든 노드에flanneld가 동작 - 네트워킹 환경 지원 (Backends) : VXLAN, host-gw, UDP, 그외에는 아직 실험적임 - 링크 링크2
- VXLAN (권장) : Port(UDP 8472), DirecRouting 지원(같은 서브넷 노드와는 host-gw 처럼 동작)
- 단, 네트워크 엔지니어분들이 알고 있는 ‘L2 확장’ 이 아니라, 각 노드마다 별도의 서브넷이 있고, 해당 서브넷 대역끼리 NAT 없이 라우팅 처리됨
- host-gw : 호스트 L2 모드?, 일반적으로 퍼블릭 클라우드 환경에서는 동작하지 않는다
- UDP (비권장) : VXLAN 지원하지 않는 오래된 커널 사용 시, Port(UDP 8285)
- VXLAN (권장) : Port(UDP 8472), DirecRouting 지원(같은 서브넷 노드와는 host-gw 처럼 동작)
- 노드마다 flannel.1 생성 : VXLAN VTEP 역할 , 뒷에 숫자는 VXLAN id 1 에 1을 의미
- 노드마다 cni0 생성 : bridge 역할
그리고 Flannel은 다음과같은 노드/파드간 통신을 구현합니다.
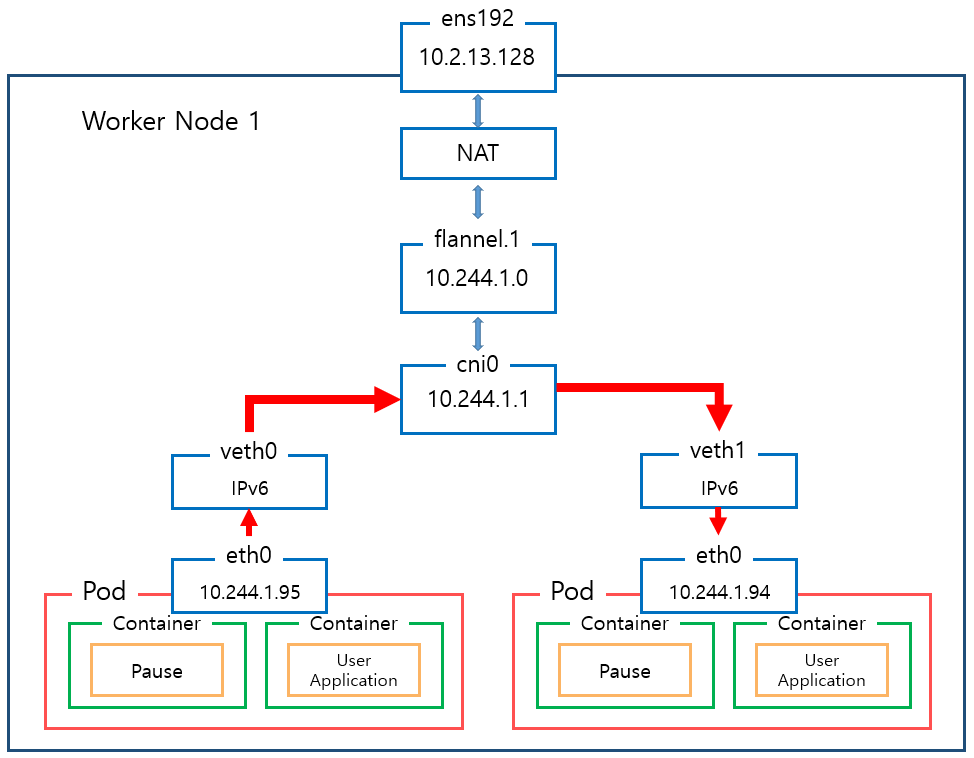
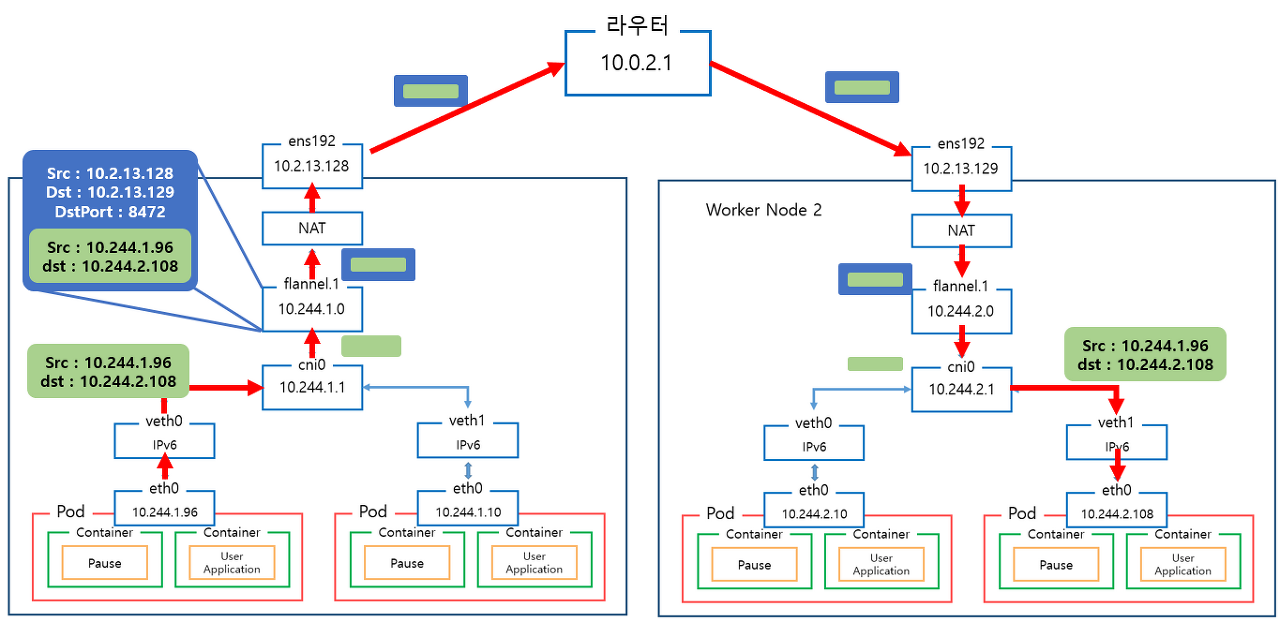
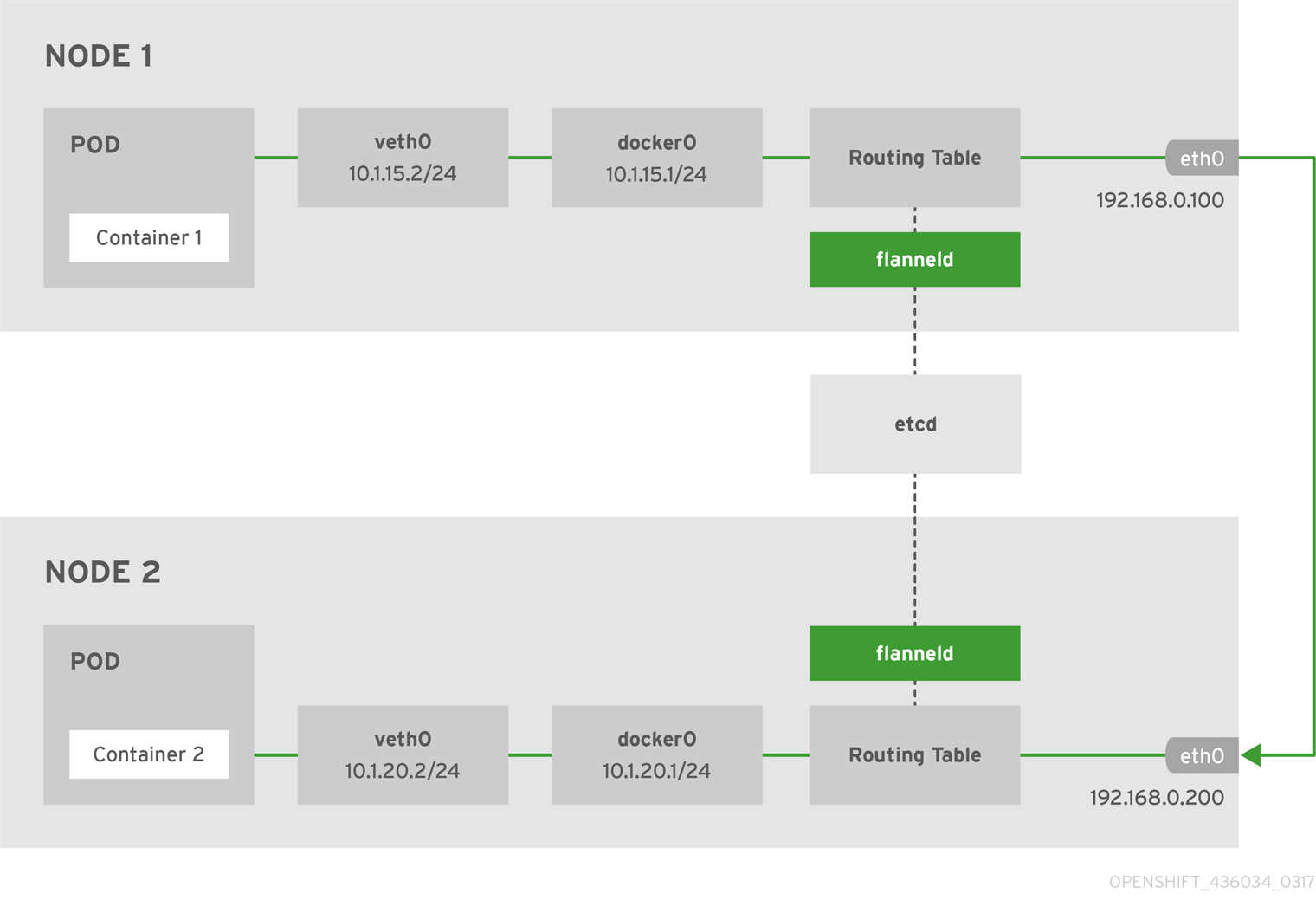
Flannel on KIND
#
cat <<EOF> kind-cni.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
labels:
mynode: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
- containerPort: 30002
hostPort: 30002
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
controllerManager:
extraArgs:
bind-address: 0.0.0.0
etcd:
local:
extraArgs:
listen-metrics-urls: http://0.0.0.0:2381
scheduler:
extraArgs:
bind-address: 0.0.0.0
- |
kind: KubeProxyConfiguration
metricsBindAddress: 0.0.0.0
- role: worker
labels:
mynode: worker
- role: worker
labels:
mynode: worker2
networking:
disableDefaultCNI: true
EOF
kind create cluster --config kind-cni.yaml --name myk8s --image kindest/node:v1.30.4
Kind 클러스터를 배포한 후에는, 각 노드가 같은 네트워크 브릿지를 사용 할 수 있도록 설정을 해주어야합니다.
kind bridge configuration
docker exec -it **myk8s-control-plane bash**
---------------------------------------
apt install golang -y
git clone https://github.com/containernetworking/plugins
chmod +x build_linux.sh
#
build_linux.sh
exit
---------------------------------------
# 자신의 PC에 복사
docker cp myk8s-control-plane:/opt/cni/bin/bridge .
ls -l bridge
docker cp bridge myk8s-control-plane:/opt/cni/bin/bridge
docker cp bridge myk8s-worker:/opt/cni/bin/bridge
docker cp bridge myk8s-worker2:/opt/cni/bin/bridge
docker exec -it myk8s-control-plane chmod 777 /opt/cni/bin/bridge
docker exec -it myk8s-worker chmod 777 /opt/cni/bin/bridge
docker exec -it myk8s-worker2 chmod 777 /opt/cni/bin/bridge
docker restart myk8s-control-plane myk8s-worker myk8s-worker2
FLANNEL CNI 배포
# 배포 확인
kind get clusters
kind get nodes --name myk8s
kubectl cluster-info
# 노드 사전준비
docker exec -it myk8s-control-plane sh -c 'apt update && apt install tree jq psmisc lsof wget bridge-utils tcpdump iputils-ping htop git nano -y'
docker exec -it myk8s-worker sh -c 'apt update && apt install tree jq psmisc lsof wget bridge-utils tcpdump iputils-ping -y'
docker exec -it myk8s-worker2 sh -c 'apt update && apt install tree jq psmisc lsof wget bridge-utils tcpdump iputils-ping -y'
# Flannel cni 설치
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
배포할때 bridge 관련 문제가 있어 설정을 선행해주었는데도 NOT READY 상태에 들어가있었는데
그냥 CNI 가 없어서 발생하는 문제였습니다.
Flannel 정보 확인
#
kubectl get ds,pod,cm -n kube-flannel -owide
kubectl describe cm -n kube-flannel kube-flannel-cfg
# iptables 정보 확인
for i in filter nat mangle raw ; do echo ">> IPTables Type : $i <<"; docker exec -it myk8s-control-plane iptables -t $i -S ; echo; done
for i in filter nat mangle raw ; do echo ">> IPTables Type : $i <<"; docker exec -it myk8s-worker iptables -t $i -S ; echo; done
for i in filter nat mangle raw ; do echo ">> IPTables Type : $i <<"; docker exec -it myk8s-worker2 iptables -t $i -S ; echo; done
# flannel 정보 확인 : 대역, MTU
for i in myk8s-control-plane myk8s-worker myk8s-worker2; do echo ">> node $i <<"; docker exec -it $i cat /run/flannel/subnet.env ; echo; done
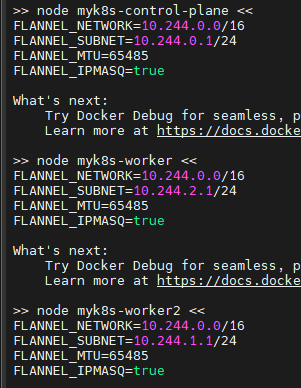
각 워커별 네트워크 정보들을 확인합니다
# 브리지 정보 확인
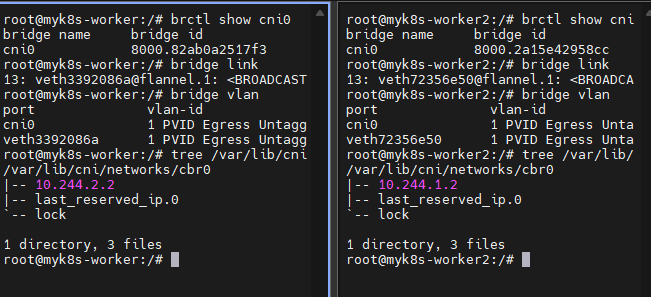
brctl show cni0
# 브리지 연결 링크(veth) 확인
bridge link
# 브리지 VLAN 정보 확인
bridge vlan
# cbr(custom bridge) 정보 : kubenet CNI의 bridge - [링크](https://kubernetes.io/ko/docs/concepts/extend-kubernetes/compute-storage-net/network-plugins/#kubenet)
tree /var/lib/cni/networks/cbr0
[심화] 파드에 IP 할당 되기 까지
(노드에 파드 IP 대역 할당 내용 포함) - 링크
-
K8S 클러스터에서 파드가 사용할 대역을 kubeadm 실행 시 설정 할 수 있다 ⇒ kind 시 기본값으로 pod-network-cidr=10.244.0.0/16 대역을 사용한다 - 링크
# init kubernetes kubeadm init --token 123456.1234567890123456 --token-ttl 0 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=<control-plane 컨테이너의 IP> -
워커 노드가 마스터 노드에 조인(Join) 시점에 ‘kube-controller-manager’ 파드가 pod-network-cidr 대역 중에서 각 ‘워커 노드‘마다 충돌되지 않는 podCIDR 을 할당한다.
# 파드 확인 kubectl get pod -n kube-system -l component=kube-controller-manager # kube-controller-manager 파드의 CIDR allocator 동작 로그 확인 kubectl logs -n kube-system -l component=kube-controller-manager | grep CIDR I1031 15:21:13.763667 1 range_allocator.go:116] No Secondary Service CIDR provided. Skipping filtering out secondary service addresses. I1031 15:21:13.964982 1 range_allocator.go:172] Starting range CIDR allocator # 워커 노드마다 할당된 dedicated subnet (podCIDR) 확인 kubectl get nodes -o jsonpath='{.items[*].spec.podCIDR}' -
이후 파드가 특정 워커 노드에 스케줄(할당) 시 파트에 IP를 할당하는 과정
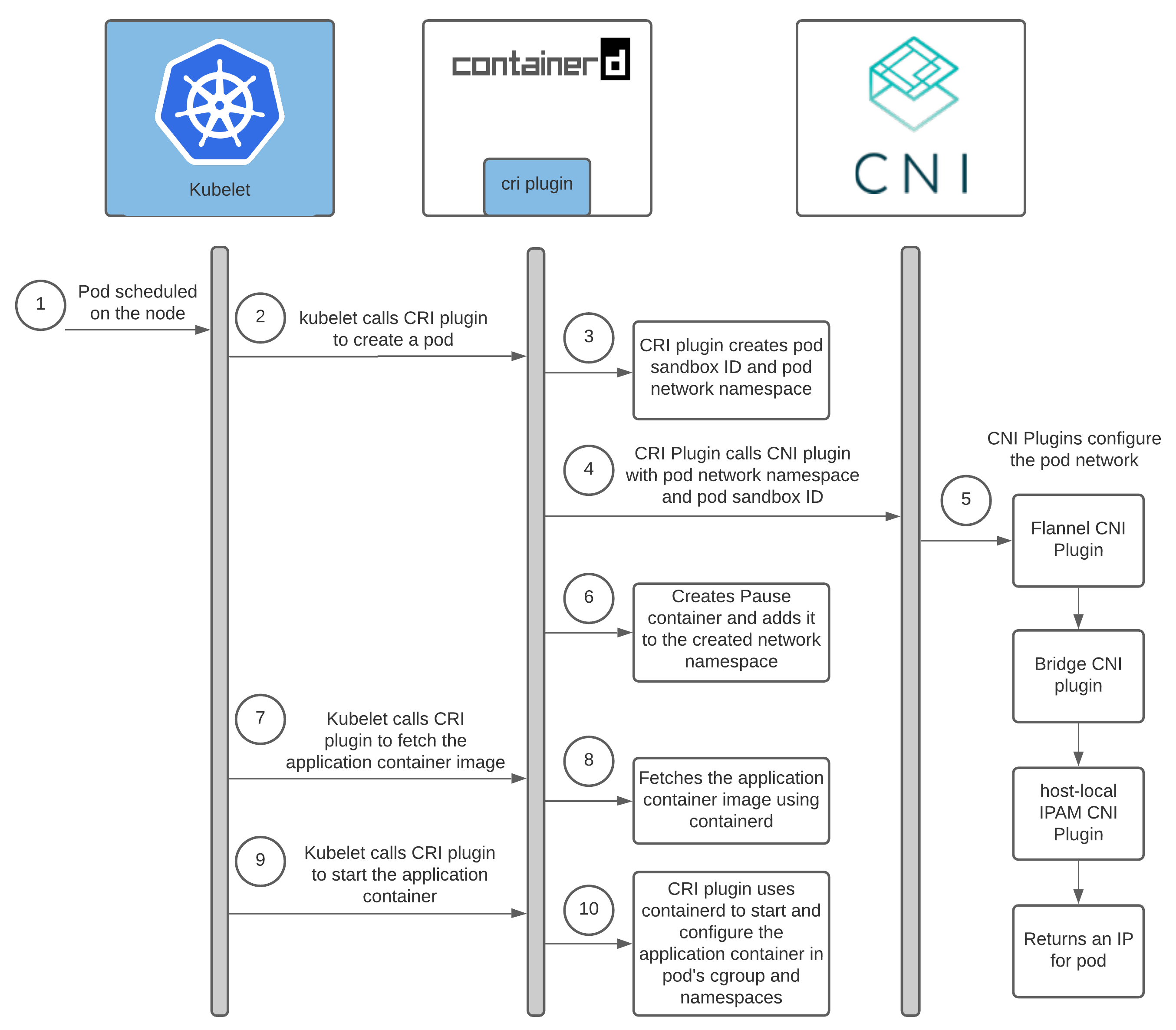
# 워커노드에서 확인 docker exec -it myk8s-worker bash --------------------------------- # 기본 flannel 플러그인 정보 확인 cat /etc/cni/net.d/10-flannel.conflist | jq { "name": "cbr0", "cniVersion": "0.3.1", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } # 해당 노드의 flannel 적용된 podCIDR 과 그와 network metadata 정보 cat /run/flannel/subnet.env FLANNEL_NETWORK=10.244.0.0/16 FLANNEL_SUBNET=10.244.1.1/24 FLANNEL_MTU=65485 FLANNEL_IPMASQ=true
이번 과정에서는 CRI - CNI 까지만 다뤘지만, 상황에따라 CSI 와의 sequential 한 상관관계가 있을수도 있습니다.
예를들어…
운영중인 클러스터에서 볼륨에 문제가 생겨 CSI Driver가 PV를 attach 하지못하는 상황이 발생합니다.
이 상황이 몇초가 아니라 분단위로 넘어갈때도 있고, 별도의 조치가 필요한 상황도 발생을 합니다.
이때 볼륨 마운트가 되지않을경우 pod ip 자체가 할당이 되지않습니다.
조금 더 살펴보기위해 재밌는 feature 들을 가져와봤습니다.
CNI의 IPAM 관리
쿠버네티스에서는 pod의 ip와 mac을 매번 무작위로 만들지만, static하게 고정 할 수 있습니다.
flannel은 아니고 calico 기준으로의 이야기입니다.
apiVersion: v1
kind: Pod
metadata:
name: example-pod
annotations:
cni.projectcalico.org/ipAddrs: "[\"192.168.1.100\"]"
cni.projectcalico.org/mac: "EE:EE:EE:EE:EE:EE"
spec:
containers:
- name: example
image: nginx
이런식으로 말이죠.
물론 저 대역은 calico에서 관리하는 영역이여야하겠지만, 저런식으로 구성을하면 저 pod가 뜰때 항상 같은 pod ip와 mac 주소를 갖게 할 수 있습니다.
그럼 어떻게 중복을 방지할까요?
정답은 CNI에서 관리하는 IPAM에 있는데,
IPAM configuration은 다음 문서에서 참조가 가능합니다.
별도 설정이 존재하지만, strictAffinity 를 활성화하면 특정 pod들에 해당해둔 pod ip , mac을 고정할경우, 해당 대역들을 무작위로 배치하는 IPAM 대역에서 제외합니다.
이로서 중복으로 같은 IP 할당을 방지할수있습니다.